Beginner’s Guide to Transformer Models: From Embeddings to Multi-Head Attention

CSE Student & a Passionate Coder
Transformers power today’s smartest AI — from ChatGPT to Google Translate.
But what makes them so powerful? 🤔
In this blog, we’ll break down transformer architecture into simple, bite-sized chunks — using fun examples like cats, dogs, and banks
⚡ What is Transformer Architecture?
Transformers are a deep learning model used in NLP (Natural Language Processing) and beyond.
Instead of reading words one by one like older models (RNNs), transformers look at all words together and understand relationships.
👉 Think of it like reading a whole paragraph at once instead of word-by-word.
📌 Step 1: Vector Embeddings
Words are just text → Machines don’t understand text.
So, we convert words into vectors (numbers) using embeddings.
Example:
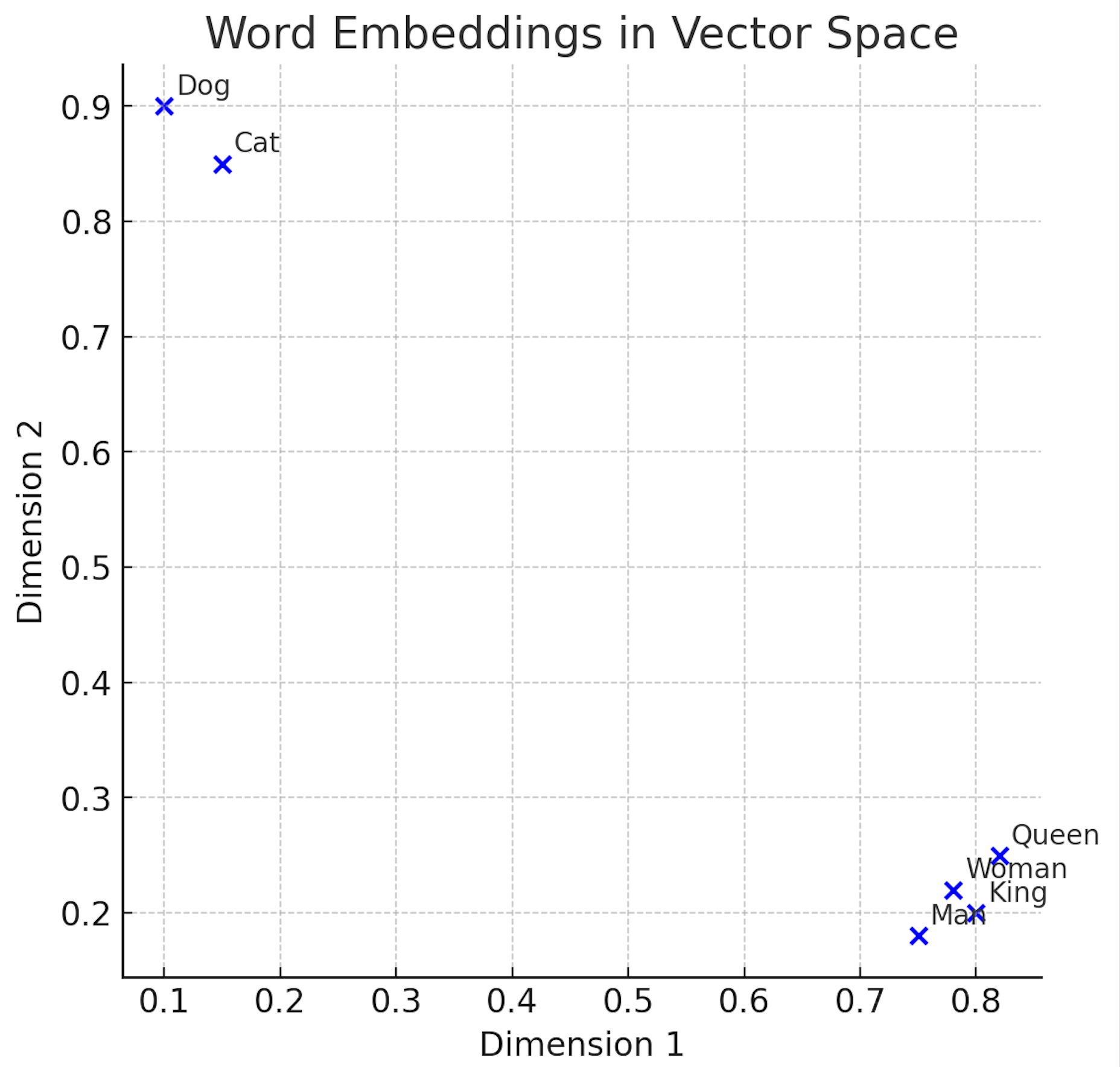
“Dog” → [0.12, 0.95, 0.33]
“Cat” → [0.14, 0.92, 0.29]
Similar words get vectors that are close in space.
💡 Example:
"King – Man + Woman = Queen" → Shows how embeddings capture meaning!
📌 Step 2: Positional Encoding
Transformers don’t naturally know word order.
To fix this, we add positional encodings.
Example:
Sentence 1: “Dog chases Cat”
Sentence 2: “Cat chases Dog”
Same words, different meaning! Order matters.
Positional encoding assigns unique values to word positions, so transformers understand who chased whom.
📌 Step 3: Self-Attention (Understanding Context)
Self-attention tells the model which words to focus on when reading a sentence.
Example:
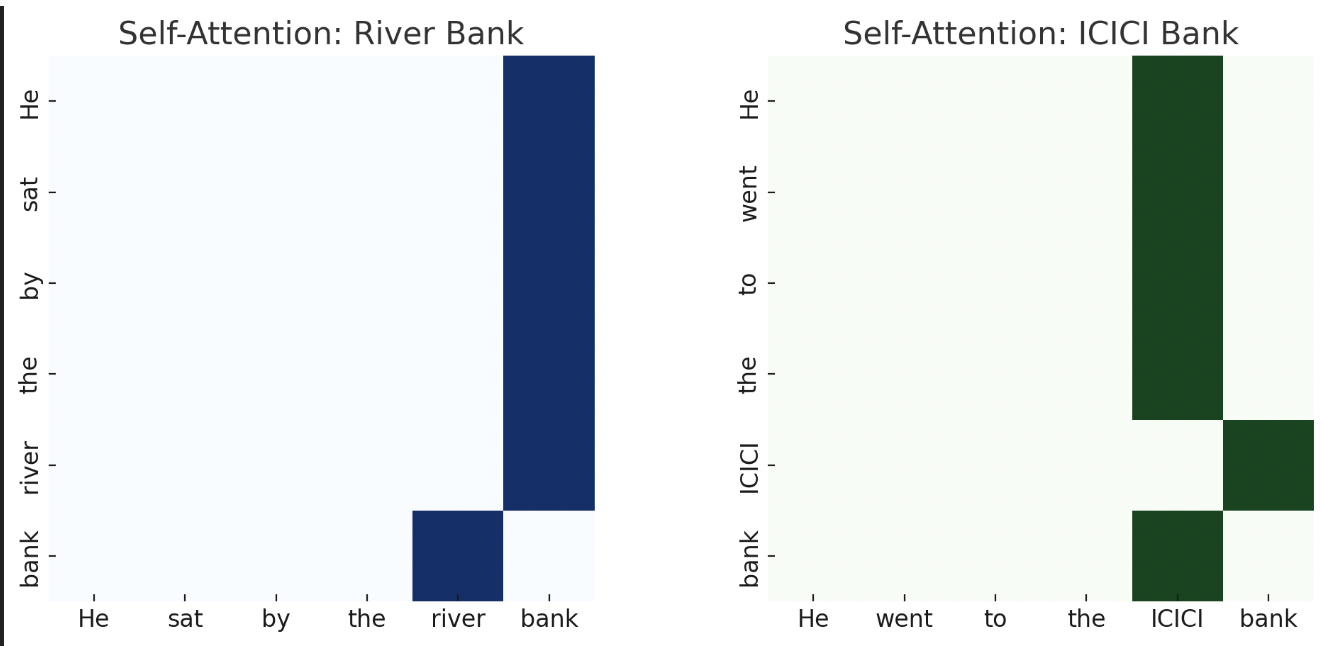
Word: “Bank”
Sentence A: “He sat by the river bank.” 🌊
Sentence B: “He went to the ICICI bank.” 🏦
Self-attention helps the model figure out which “bank” is correct by looking at context words like “river” or “ICICI”.
👉 Each word looks at every other word → learns relationships & meaning.
📌 Step 4: Multi-Head Attention (Multiple Perspectives)
One attention isn’t enough! Multi-head attention lets the model look at text from different angles.
Example: Sentence: “A train is moving. There is a cute dog. The dog is a Labrador.” 🚆🐶
Head 1 → Focuses on subject relationships (train → moving, dog → Labrador).
Head 2 → Focuses on attributes (cute → dog).
Head 3 → Focuses on sentence order.
💡 Together, these “heads” combine perspectives for better context/understanding.
🌟 Key Takeaways
Transformer architecture is the backbone of modern AI.
Vector embeddings convert words into machine-friendly numbers.
Positional encoding helps models understand word order.
Self-attention allows context-based meaning (river bank vs ICICI bank).
Multi-head attention looks at text from multiple angles for deeper understanding.

